Commencer#
Introduction#
Ouvrez QGIS sur votre ordinateur. Pour avoir accès aux messages du journal, activez le panneau « Journal des messages » dans QGIS en allant à Vue > Panneau > Journal des messages dans le Menu. Lorsque vous utilisez un plugin, c’est aussi une bonne habitude d’ouvrir la console Python dans QGIS pour avoir accès aux messages Python retournés dans la console. Pour l’ouvrir, cliquez sur l’icône Python ![]() dans la barre d’outils « Extensions ». Si la barre d’outils n’est pas visible, activez-la en allant dans
dans la barre d’outils « Extensions ». Si la barre d’outils n’est pas visible, activez-la en allant dans Vue > Barres d'outils > Extensions dans le menu.
Une fois le plugin installé (voir les instructions d”installation), ouvrez le plugin en cliquant sur son icône ![]() . Vous devriez voir les versions des dépendances installées dans votre environnement écrites dans la console Python. Vérifiez que ces numéros de version correspondent à la dernière version de chaque dépendance. Sinon, mettez à jour les dépendances.
. Vous devriez voir les versions des dépendances installées dans votre environnement écrites dans la console Python. Vérifiez que ces numéros de version correspondent à la dernière version de chaque dépendance. Sinon, mettez à jour les dépendances.
osmconvert 0.8.10
osmfilter 1.4.4
geefcc 0.1.3
pywdpa 0.1.6
forestatrisk 1.2
riskmapjnr 1.3
Pour tester le plugin et avoir un premier aperçu de ses fonctionnalités, essayez-le sur une petite zone d’intérêt (AOI) telle que l’île Martinique (1128 km2) qui a le code iso MTQ. Tester le plugin sur une petite AOI a l’avantage de rendre les calculs rapides afin que vous puissiez voir directement les sorties, interpréter les résultats et comprendre le fonctionnement du plugin.
Pour mieux comprendre les différentes étapes, il faut garder à l’esprit que nous considérons différentes périodes et dates pour la calibration et la validation des modèles.
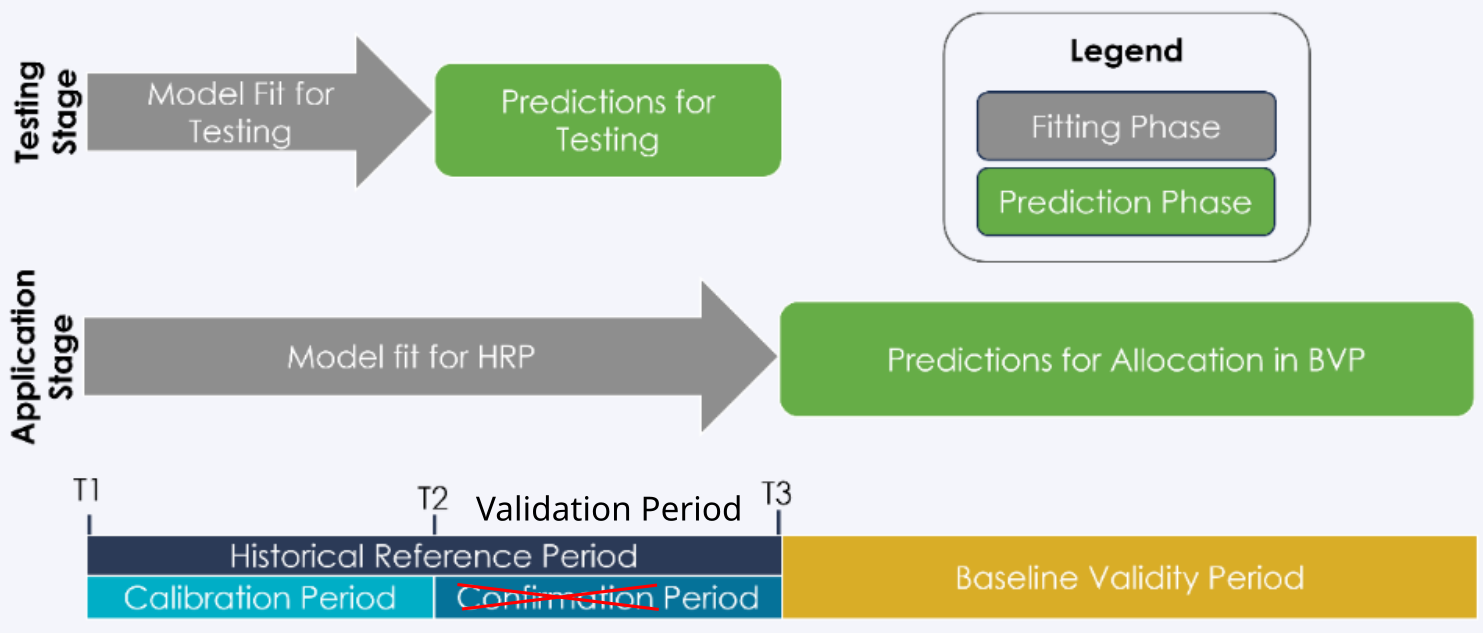
Dates et périodes utilisées pour calibrer et valider les modèles. Modifié à partir de Verra’s VT0007. Dans notre cas, nous avons renommé la période allant de t2 à t3 « période de validation » au lieu de « période de confirmation ».#
Obtention des variables (Get variables)#
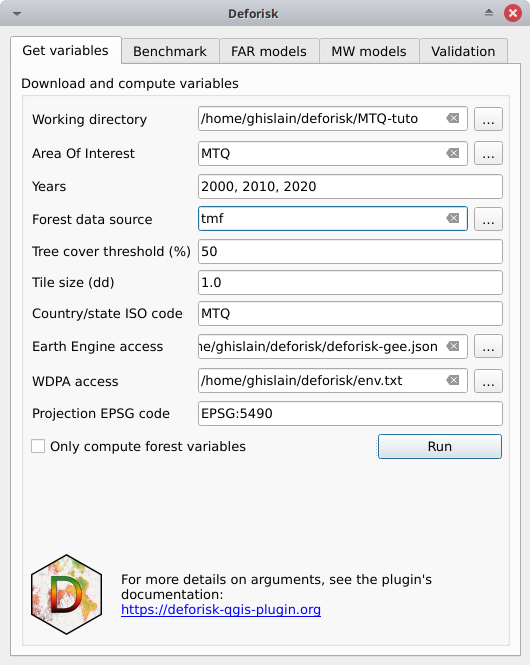
Working directory: Répertoire de travail. Sélectionnez votre répertoire de travail. Ici/home/<username>/deforisk/MTQ-tuto, mais cela pourrait êtreC:\Users\<username>\deforisk\MTQ-tutosur Windows par exemple.Area Of Interest: Zone d’étude cible. MTQYears: Années. 2000, 2010, 2020Forest data source: Source de données forestières. tmfTree cover threshold (%): Seuil de couverture arborée. 50 (peut être laissé vide, pas utile ici pour la source de données tmf)Tile size (dd): Taille de la tuile. 1Country/state ISO code: Code ISO du pays/de l’état, MTQEarth Engine access: Nom du projet Google Cloud avec accès à Earth Engine ou chemin d’accès à un fichier de clé privée JSON pour le compte de service.WDPA access: Clé d’API WDPA personnelle ou chemin d’accès à un fichier texte avec la variable environnementale WDPA_KEY.Projection EPSG code: Code EPSG de la projection. EPSG:5490Only compute forest variables: Calculer uniquement les variables forestières. non coché, les données seront téléchargées à partir de jeux de données globaux (SRTM, WDPA, OSM) et les variables explicatives autres que les variables liées à la forêt seront calculées.
Avertissement
Pour les utilisateurs de Windows, choisissez un répertoire de travail avec un chemin court (par exemple C:\Users\<username>\<dirname>). Les longs chemins d’accès aux fichiers peuvent poser des problèmes d’accès aux fichiers sous Windows.
Cliquez sur le bouton Run. Une carte des changements du couvert forestier apparaît dans la liste des couches de QGIS (voir l’image ci-dessous et cliquer pour l’agrandir) et une figure représentant le changement du couvert forestier fcc123.png est créée dans le dossier outputs/variables. De nouveaux dossiers sont créés dans le répertoire de travail, dont le dossier data_raw qui contient les données brutes avec les fichiers intermédiaires et le dossier data qui contient les données traitées utilisées pour les modèles et les traces. Vous pouvez visualiser le réseau routier par exemple en ajoutant le fichier vectoriel roads_proj.shp, qui est situé dans le répertoire data_raw, dans QGIS.
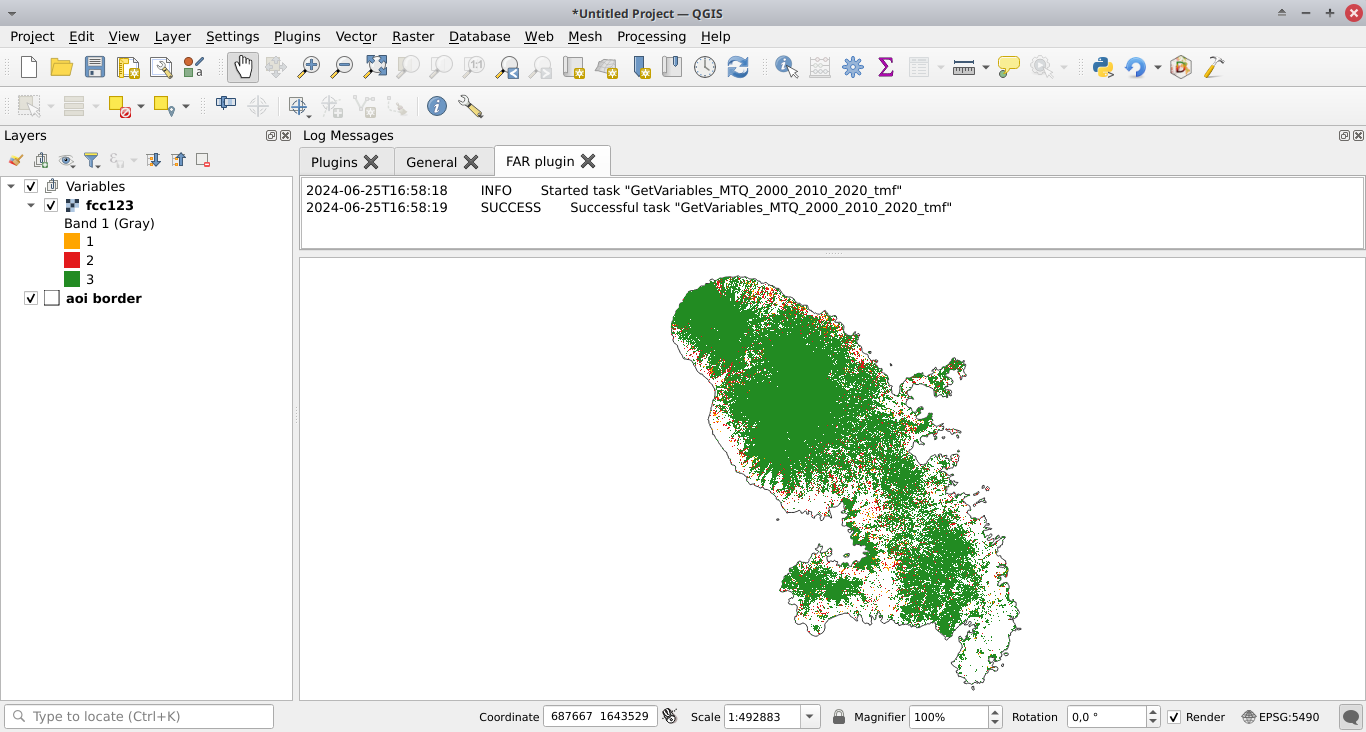
Si vous souhaitez sauter cette étape, vous pouvez télécharger un fichier zip comprenant toutes les données de l’exemple MTQ.
Modèle de référence (Benchmark)#
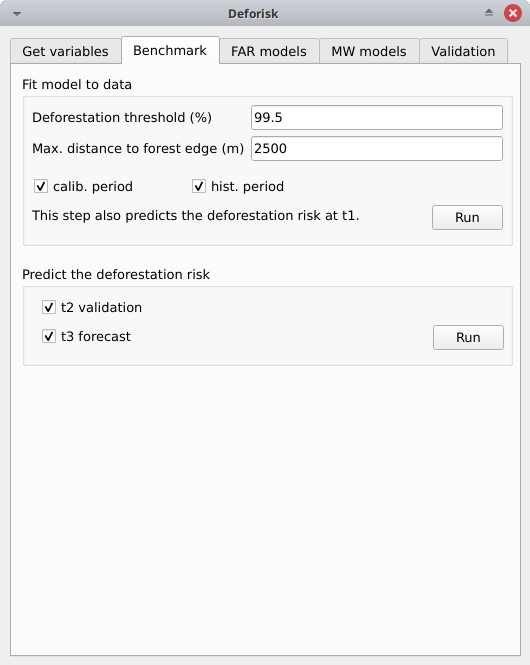
Ajuster le modèle aux données (Fit model to data)#
Deforestation threshold (%): 99.5Max. distance to forest edge (m): 2500calib. period: Si cette case est cochée, le modèle est ajusté sur la période d’étalonnage (t1–t2).hist. period: Si cette case est cochée, le modèle est ajusté sur la période historique (t1–t3).
Cliquez sur le bouton Run pour estimer le risque de déforestation avec le modèle de référence et prédire le risque de déforestation à t1 en utilisant les données de la période de calibration et de la période historique. Les cartes comportant des classes de risque de déforestation sont ajoutées à la liste des couches QGIS (voir l’image ci-dessous).
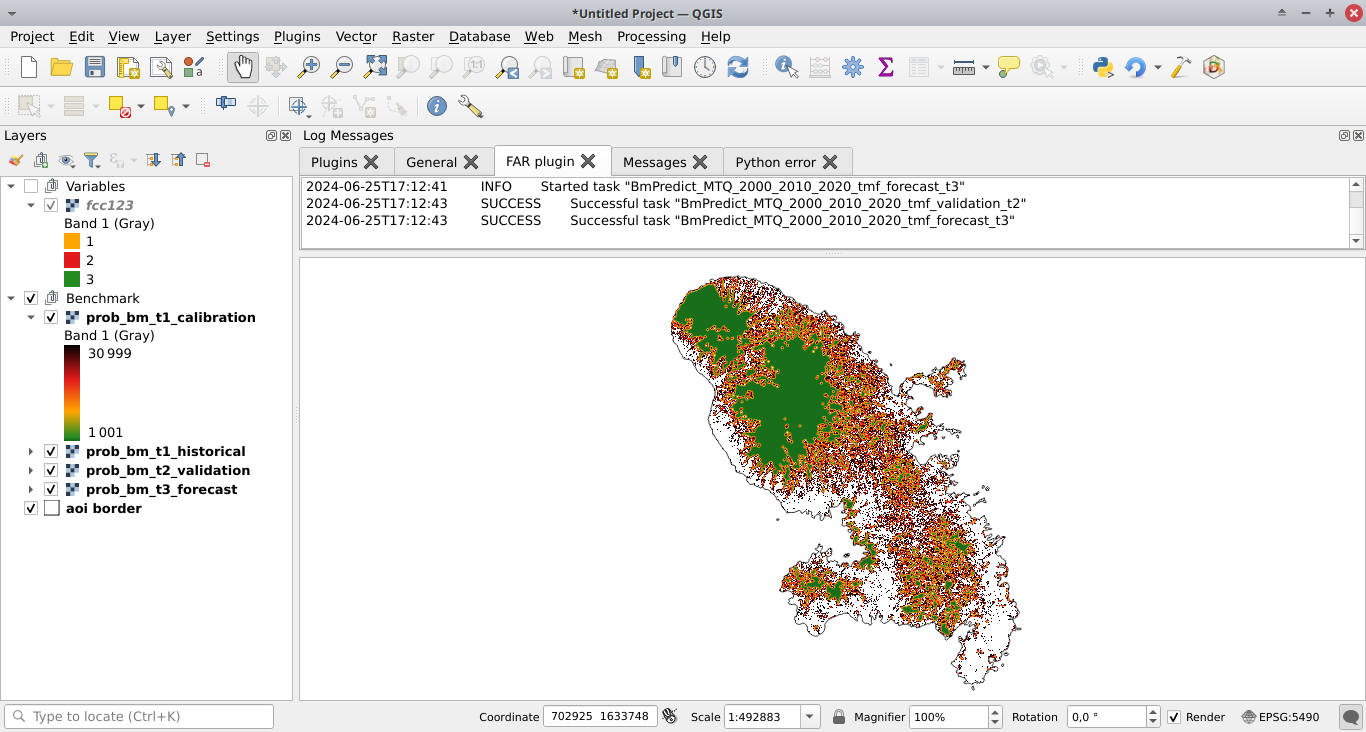
De nouveaux dossiers contenant les résultats sont créés dans le répertoire outputs/rmj_benchmark/ pour chaque période. En particulier, les dossiers de sortie comprennent le fichier <period>/perc_dist.png. Ce fichier montre la figure de la déforestation cumulée en fonction de la distance à la lisière de la forêt et indique le seuil de distance (ici 240 m pour la période de calibration).
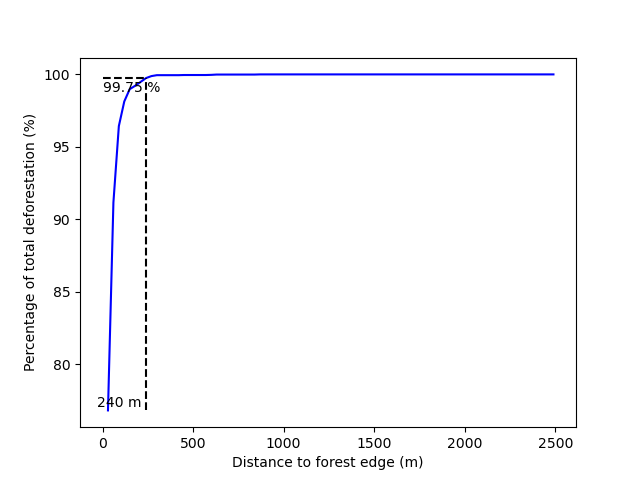
Seuil de distance pour la période de calibration.#
Les dossiers de sortie comprennent également le tableau <period>/defrate_cat_bm_<period>.csv qui montre les taux de déforestation pour chaque classe de risque de déforestation (voir les détails ici).
cat |
nfor |
ndefor |
rate_obs |
rate_mod |
rate_abs |
time_interval |
pixel_area |
defor_dens |
|---|---|---|---|---|---|---|---|---|
1001 |
33433 |
0 |
0.0 |
0.0 |
0.0 |
10 |
0.09 |
0.0 |
1002 |
12965 |
0 |
0.0 |
0.0 |
0.0 |
10 |
0.09 |
0.0 |
1003 |
91686 |
19 |
2.072e-05 |
2.072e-04 |
2.072e-04 |
10 |
0.09 |
1.865e-06 |
1004 |
82279 |
5 |
6.077e-06 |
6.076e-05 |
6.076e-05 |
10 |
0.09 |
5.469e-07 |
2001 |
1373 |
0 |
0.0 |
0.0 |
0.0 |
10 |
0.09 |
0.0 |
Prédire le risque de déforestation (Predict the deforestation risk)#
t2 validation: Coché, calcule les prédictions à t2 pour la validation (en utilisant le modèle de référence ajusté sur la période de calibration).t3 forecast: Coché, calcule les prédictions à t3 pour les prévisions (en utilisant le modèle de référence ajusté sur la période historique).
Cliquez sur le bouton Run pour prédire le risque de déforestation à t2 et t3 en utilisant le modèle de référence. Les cartes avec les classes de risque de déforestation sont ajoutées à la liste des couches QGIS et de nouveaux fichiers sont ajoutés aux dossiers de sortie.
Modèles forestatrisk (FAR models)#
Échantillonnage des observations (Sample observations)#
N# samples: 10000Adapt sampling: Coché, le nombre d’observations est proportionnel à la surface forestière.Random seed: 1234Spatial cell size (km): 2calib. period: Si cette case est cochée, les observations sont échantillonnées pour la période d’étalonnage (t1–t2).hist. period: Si cette case est cochée, les observations sont échantillonnées pour la période historique (t1–t3).
Avertissement
Pour les grandes juridictions, afin d’éviter de calculer trop de paramètres pour les effets aléatoires spatiaux, la taille de la cellule spatiale est fixée à ~10 km.
En appuyant sur le bouton Run dans cette boîte, vous échantillonnez les observations. Lorsque l’opération est terminée, les observations échantillonnées apparaissent dans la liste des couches QGIS.
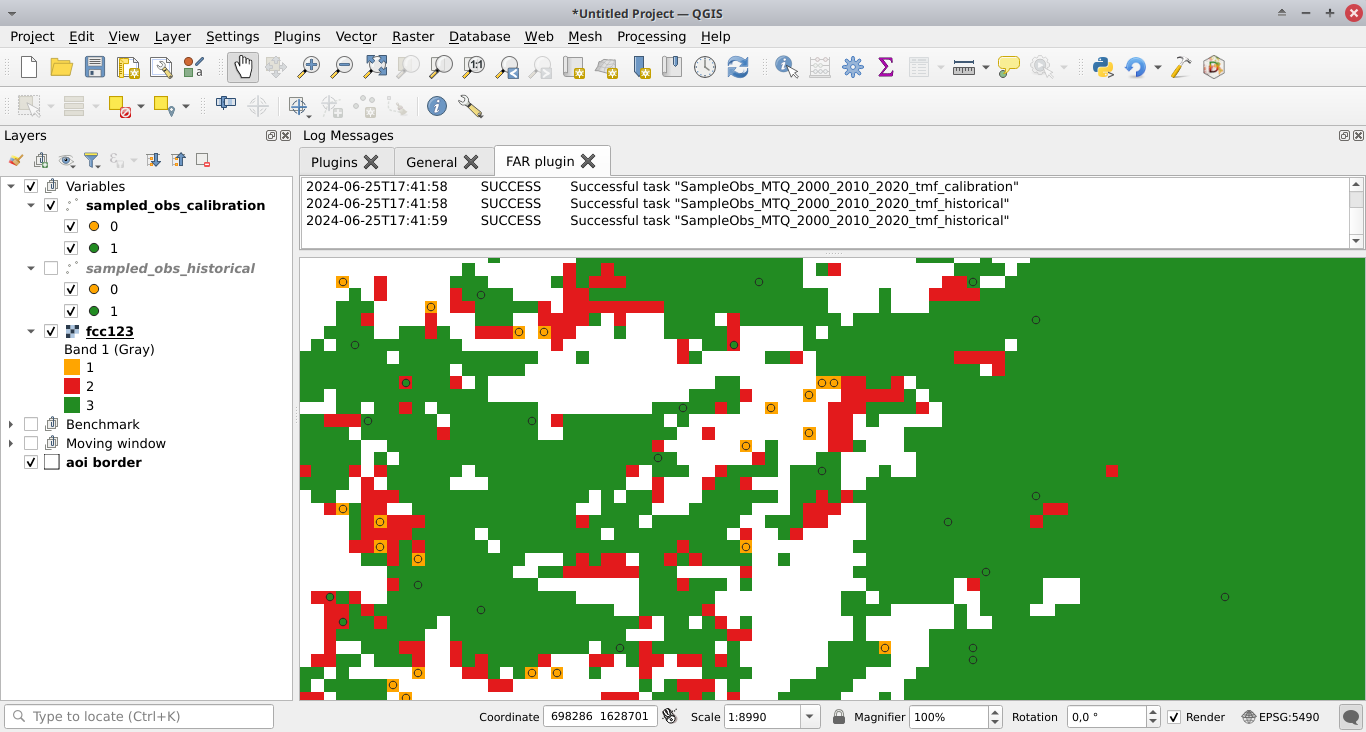
De nouveaux dossiers contenant les résultats sont créés dans le répertoire outputs/far_models/, y compris le fichier <period>/sample.txt qui est le jeu de données d’observations avec les valeurs des variables.
altitude |
dist_edge |
dist_river |
dist_road |
dist_town |
fcc |
pa |
slope |
X |
Y |
cell |
|---|---|---|---|---|---|---|---|---|---|---|
56 |
30 |
750 |
0 |
150 |
0 |
1 |
6 |
700155 |
1645545 |
63 |
56 |
30 |
750 |
0 |
150 |
0 |
1 |
6 |
700185 |
1645545 |
63 |
100 |
30 |
875 |
0 |
1657 |
0 |
1 |
5 |
698265 |
1645425 |
62 |
93 |
30 |
600 |
0 |
1358 |
0 |
1 |
8 |
698565 |
1645425 |
62 |
68 |
30 |
300 |
0 |
335 |
0 |
1 |
7 |
699615 |
1645425 |
63 |
Ajuster le modèle aux données (Fit model to data)#
List of variables: Laisser vide, la formule par défaut sera utilisée:C(pa) + altitude + pente + dist_edge + dist_road + dist_river + dist_town.Starting values for betas: -99Prior Vrho: -1MCMC: 100Variable selection: Ne pas cocher, pas de sélection de variables (accélère les calculs pour cet exemple).calib. period: Coché, les modèles sont ajustés sur la période de calibration (t1–t2).hist. period: Coché, les modèles sont ajustés sur la période historique (t1–t3).
En appuyant sur le bouton Run dans cette boîte, le modèle statistique sera ajusté aux observations de déforestation. Trois modèles statistiques sont ajustés (modèle iCAR, GLM, et modèle Random Forest). De nouveaux fichiers sont ajoutés aux dossiers outputs/far_models/calibration et outputs/far_models/historical. En particulier, le fichier summary_icar.txt est le résumé du modèle iCAR avec la moyenne, l’écart-type et les intervalles de crédibilité pour les paramètres du modèle.
Mean |
Std |
CI_low |
CI_high |
|
|---|---|---|---|---|
Intercept |
-3.39 |
0.158 |
-3.7 |
-3.1 |
C(pa) [T.1.0] |
-0.0915 |
0.122 |
-0.282 |
0.172 |
scale(dist_edge) |
-10.3 |
0.417 |
-11.1 |
-9.63 |
scale(dist_road) |
-0.256 |
0.0537 |
-0.36 |
-0.144 |
scale(dist_town) |
0.0342 |
0.0464 |
-0.0551 |
0.123 |
scale(dist_river) |
-0.0817 |
0.0544 |
-0.188 |
0.0199 |
échelle(altitude) |
-0.554 |
0.0809 |
-0.728 |
-0.4 |
scale(slope) |
-0.532 |
0.0392 |
-0.611 |
-0.457 |
Vrho |
6.89 |
0.756 |
5.64 |
8.49 |
Deviance |
1.36e+04 |
24.9 |
1.36e+04 |
1.37e+04 |
Le fichier model_deviances.csv comprend un tableau permettant de comparer le pourcentage de déviance expliquée entre les modèles.
model |
déviance |
perc |
|---|---|---|
nul |
26769.0 |
0.0 |
glm |
16864.0 |
37.0 |
rf |
6668.0 |
75.0 |
icar |
13636.0 |
49.0 |
full |
0.0 |
100.0 |
Prédire le risque de déforestation (Predict the deforestation risk)#
Spatial cell size interpolation (km): 0.1.iCAR model: Coché, calcule les prédictions avec le modèle iCAR.GLM: Coché, calcule les prédictions avec GLM.RF model: Coché, calcule les prédictions avec le modèle Random Forest.t1 calibration: Coché, calcule les prédictions à t1 en utilisant des modèles ajustés sur la période de calibration.t2 validation: Coché, calcule les prédictions à t2 pour la validation (en utilisant les modèles ajustés sur la période de calibration).t1 historical: Coché, calcule les prédictions à t1 en utilisant des modèles ajustés sur la période historique.t3 forecast: Coché, calcule les prédictions à t3 pour les prévisions (en utilisant des modèles ajustés sur la période historique).
Avertissement
Pour les grandes juridictions, afin d’éviter l’obtention d’un fichier raster volumineux (de type Float), fixer l’interpolation des effets aléatoires spatiaux à ~1km.
En appuyant sur le bouton Run dans cette boîte, les modèles statistiques seront utilisés pour les prédictions. Lorsque l’opération est terminée, des rasters représentant les classes de risque de déforestation apparaissent dans la liste des couches de QGIS. De nouveaux dossiers sont créés outputs/far_models/validation et outputs/far_models/forecast. Ils contiennent les tableaux <period>/defrate_cat_<model>_<period>.csv avec les taux de déforestation pour chaque classe de risque de déforestation (voir les détails ici).
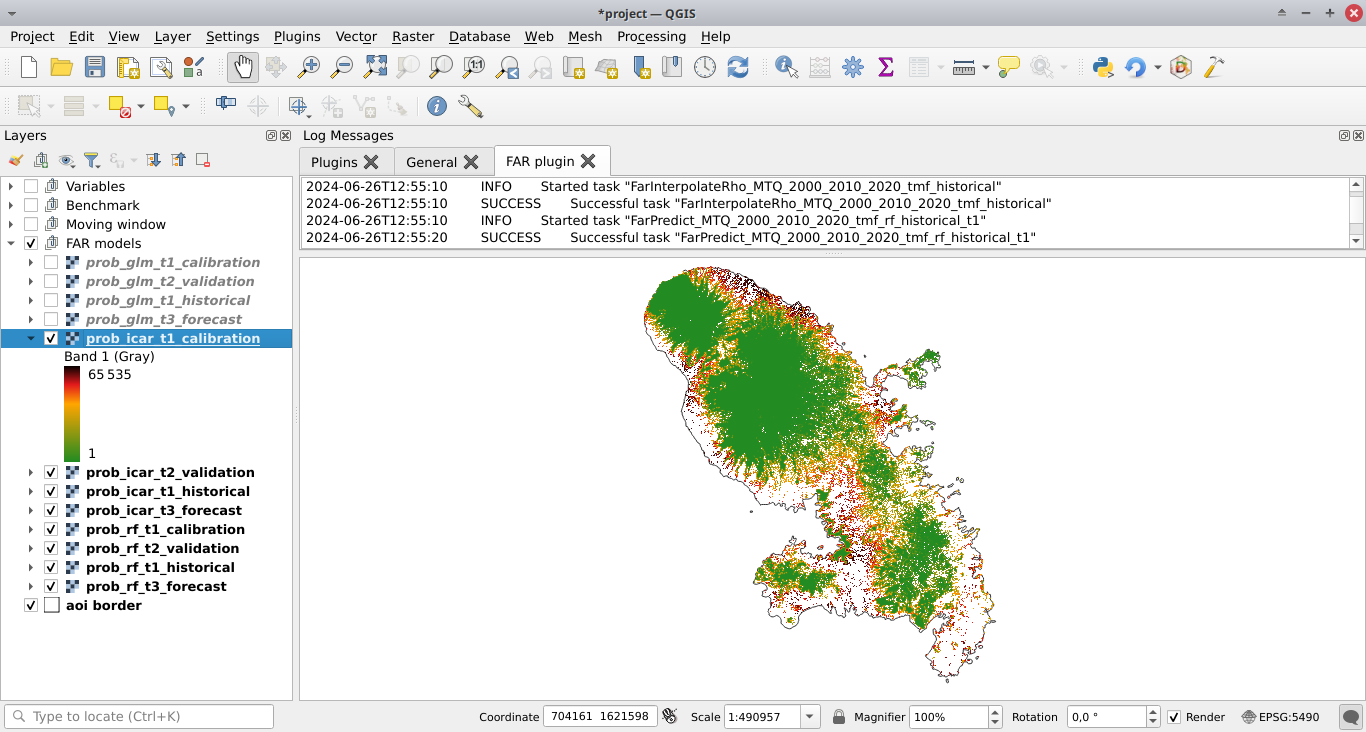
Modèles à fenêtre mobile (MW models)#
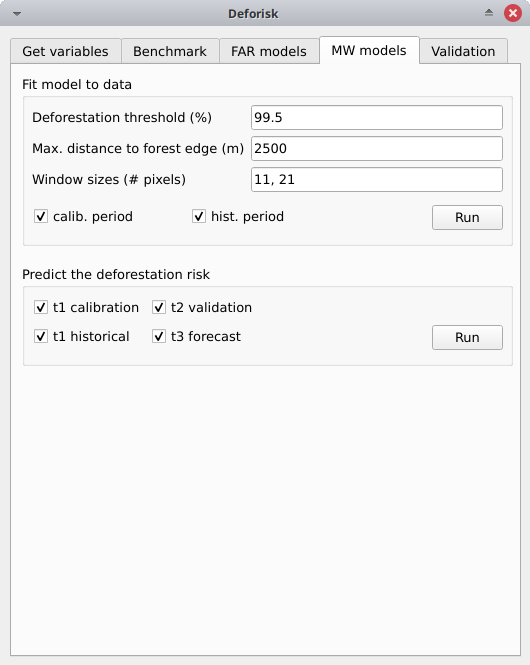
Ajuster le modèle aux données (Fit model to data)#
Deforestation threshold (%): 99.5%Max. distance to forest edge (m): 2500Window sizes (# pixels): 11, 21calib. period: Si cette case est cochée, le modèle est ajusté sur la période d’étalonnage (t1–t2).hist. period: Si cette case est cochée, le modèle est ajusté sur la période historique (t1–t3).
Note
Pour les grandes juridictions, si vous souhaitez réduire le temps de calcul, utilisez une seule taille de fenêtre mobile (par exemple 21 pixels).
Cliquez sur le bouton Run pour estimer le risque de déforestation avec le modèle de fenêtre mobile en utilisant les données de la période de calibration et de la période historique. De nouveaux dossiers contenant les résultats sont créés dans le répertoire outputs/rmj_moving_window/, y compris le fichier raster <period>/ldefrate_mw_<window_size>.tif avec les taux de déforestation locaux remis à l’échelle sur l’intervalle [2, 65535].
Prédire le risque de déforestation (Predict the deforestation risk)#
t2 validation: Coché, calcule les prédictions à t2 pour la validation (en utilisant le modèle de fenêtre mobile ajusté sur la période de calibration).t3 forecast: Coché, calcule les prédictions à t3 pour les prévisions (en utilisant le modèle de fenêtre mobile ajusté sur la période historique).
Cliquez sur le bouton Run pour prédire le risque de déforestation à t2 et t3 en utilisant le modèle de fenêtre mobile. Les cartes avec les classes de risque de déforestation sont ajoutées à la liste des couches QGIS (voir l’image ci-dessous) et de nouveaux dossiers avec les résultats sont créés dans le répertoire outputs/rmj_moving_window/, y compris les tableaux <period>/defrate_cat_mv_<window_size>_<period>.csv avec les taux de déforestation pour chaque classe de risque de déforestation (voir les détails ici).
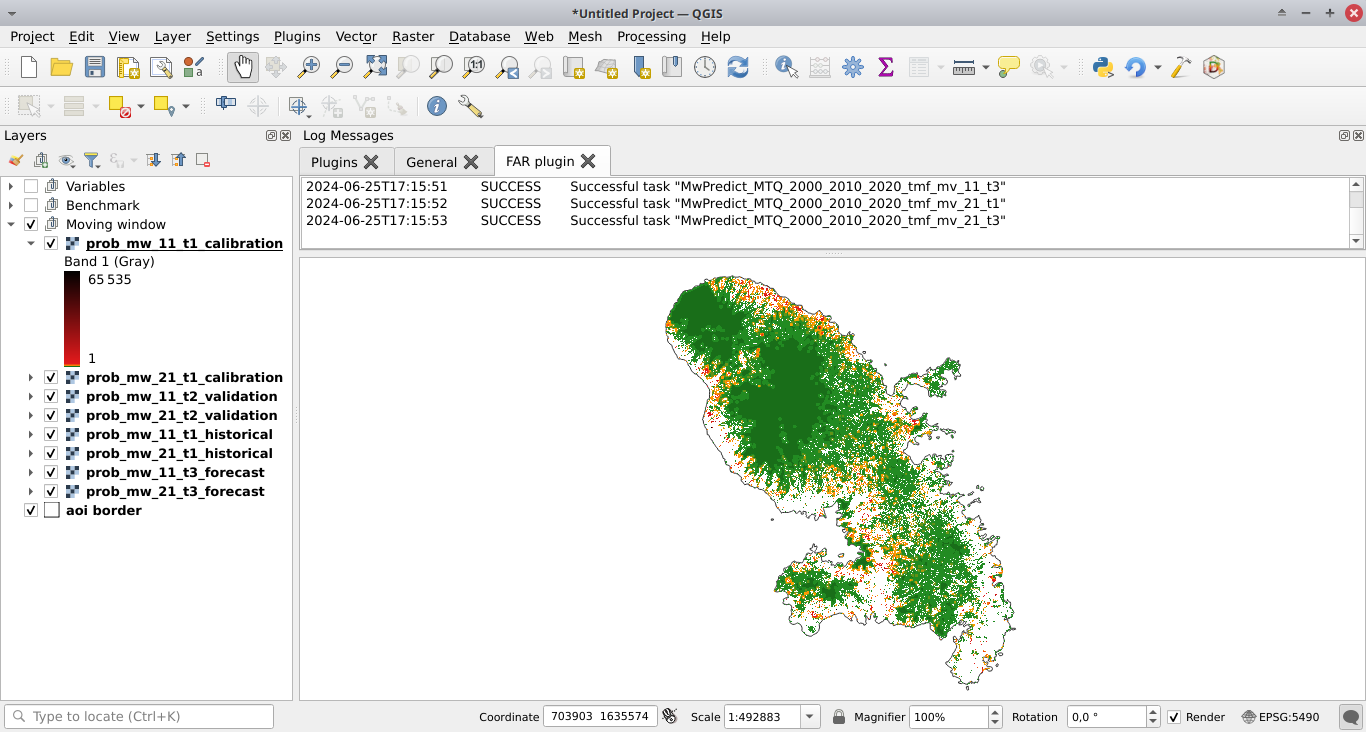
Validation#
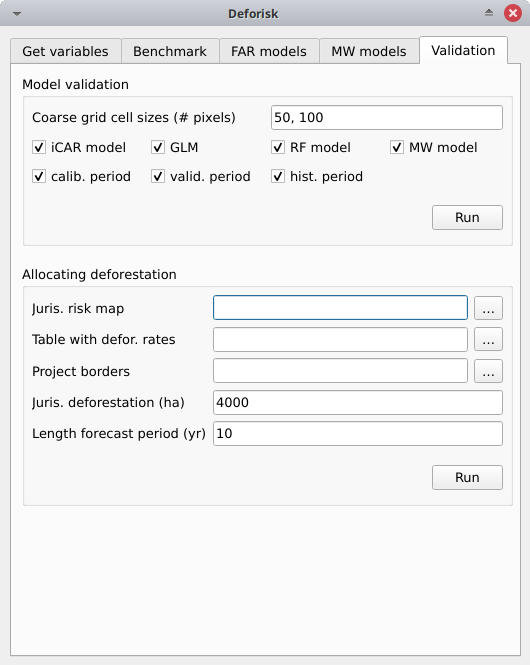
Coarse grid cell size (# pixels): 50, 100iCAR model: Coché, estime la performance du modèle iCAR.GLM: Coché, estime la performance du GLM.RF model: Coché, estime la performance du modèle Random Forest.MW model: Coché, estime la performance des modèles à fenêtre mobile.calib. period: Coché, estime la performance des modèles pour la période de calibration (t1–t2).valid. period: Coché, estime la performance des modèles pour la période de validation (t2–t3).hist. period: Coché, estime la performance des modèles pour la période historique (t1–t3).
Note
Pour les grandes juridictions, si vous souhaitez réduire le temps de calcul, n’utilisez qu’une seule taille de cellule (par exemple 100 pixels) et ne cochez que la période de validation, la seule qui comporte des observations indépendantes.
En appuyant sur le bouton Run dans cette boîte, on calcule la surface déforestée prédite dans chaque cellule de la grille pour chaque modèle et chaque période sélectionnés et on compare cette valeur à la surface déforestée observée pour la même cellule de la grille et la même période.
De nouveaux dossiers sont créés pour chaque période : outputs/model_validation/<period>/figures et outputs/model_validation/<period>/tables. Plusieurs fichiers de sortie sont ajoutés à chaque dossier.
Fichiers figures/pred_obs_<model>_<period>_<cell_size>.png qui contiennent une figure montrant la relation entre la surface déforestée prédite et la surface déforestée observée. La figure montre les valeurs de la surface déforestée prédite et observée dans chaque cellule de la grille sous forme de points et la première bissectrice (ligne 1-1). La figure indique également le nombre de cellules de la grille (équivalent au nombre de points) et les valeurs de deux des indices de performance : le \(R^{2}\) et le MedAE.
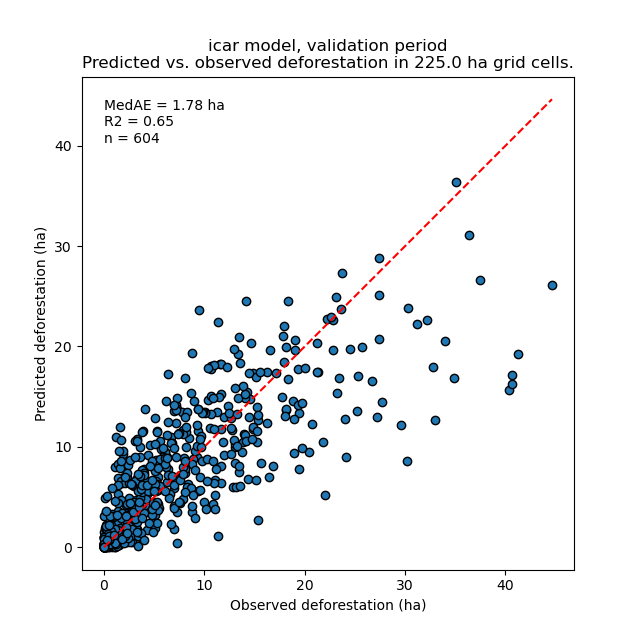
Le fichier outputs/model_validation/indices_all.csv comprend un tableau avec les indices de performance pour toutes les tailles de cellules de validation, tous les modèles et toutes les périodes. Dans cet exemple, le modèle Random Forest et le modèle iCAR sont tous deux meilleurs que le modèle de référence, quels que soient les indices de performance considérés. Le modèle iCAR est le meilleur modèle car il a l’indice MedAE le plus faible, le RMSE le plus faible et le \(R^{2}\) le plus élevé pour la période de validation qui est la seule période avec des données indépendantes (c’est-à-dire qui n’ont pas été utilisées pour calibrer les modèles). Ceci est vrai quelle que soit la taille de la cellule de validation choisie.
csize_coarse_grid |
csize_coarse_grid_ha |
ncell |
period |
model |
MedAE |
R2 |
RMSE |
wRMSE |
|---|---|---|---|---|---|---|---|---|
50 |
225.0 |
604 |
validation |
bm |
2.71 |
0.43 |
6.08 |
6.22 |
50 |
225.0 |
604 |
validation |
icar |
1.78 |
0.65 |
4.79 |
4.59 |
50 |
225.0 |
604 |
validation |
glm |
2.39 |
0.38 |
6.39 |
6.52 |
50 |
225.0 |
604 |
validation |
rf |
2.09 |
0.50 |
5.69 |
5.74 |
50 |
225.0 |
604 |
validation |
mw_11 |
2.34 |
0.56 |
7.66 |
6.83 |
50 |
225.0 |
604 |
validation |
mw21 |
2.51 |
0.56 |
7.54 |
6.66 |
Attribution de la déforestation (allocating deforestation)#
La carte du risque de déforestation obtenue avec le modèle iCAR à t3 peut être utilisée pour allouer la déforestation après l’année 2020. La carte de risque avec les classes de déforestation de 1 à 65535 et le tableau defrate_cat_icar_forecast.csv avec les taux de déforestation pour chaque classe de risque sont tous deux nécessaires pour allouer la déforestation dans le futur.
Le tableau n’inclut que les valeurs de rate_mod, les taux relatifs de déforestation spatiale du modèle iCAR estimés sur la période historique. Comme pour l’étape de validation, la déforestation relative doit être ajustée en tenant compte de la déforestation absolue (en ha) attendue dans le futur.
cat |
nfor |
ndefor |
rate_obs |
rate_mod |
rate_abs |
time_interval |
pixel_area |
defor_dens |
|---|---|---|---|---|---|---|---|---|
1 |
137575 |
0 |
0.0 |
1e-06 |
0.0 |
20 |
0.09 |
0.0 |
2 |
5425 |
0 |
0.0 |
1.6259239478743857e-05 |
0.0 |
20 |
0.09 |
0.0 |
3 |
3523 |
0 |
0.0 |
3.151847895748772e-05 |
0.0 |
20 |
0.09 |
0.0 |
4 |
2458 |
0 |
0.0 |
4.677771843623157e-05 |
0.0 |
20 |
0.09 |
0.0 |
5 |
2078 |
0 |
0.0 |
6.203695791497542e-05 |
0.0 |
20 |
0.09 |
0.0 |
En considérant une déforestation totale \(D\) (en ha) pour les \(Y\) prochaines années au niveau juridictionnel, le facteur d’ajustement est :math:rho = D / (A sum_i n_{i} theta_{m,i})`, avec \(A\) la surface du pixel en ha, le taux absolu est :math:theta_{a,i} = rho theta_{m,i}`, et la densité de déforestation est :math:delta_{i} = theta_{a,i} n- fois A / Y`. La densité de déforestation :math:delta_{i}` est utilisée pour prédire la quantité de déforestation (en ha/an) pour chaque pixel forestier appartenant à une classe donnée de risque de déforestation pour les prochaines \(Y\) années (pour les notations, voir les détails ici).
La carte de risque ainsi que le tableau des densités de déforestation calculées peuvent être utilisés pour allouer proportionnellement des fractions de la déforestation attendues au sein de la juridiction (dans le contexte de VMD0055) ou du FREL de la juridiction (dans le contexte du VCS Jurisdictional and Nested REDD+ Framework) aux projets ou programmes mis en œuvre au sein de la juridiction. Pour ce faire, un tableau avec le nombre de pixels pour chaque classe de risque de déforestation dans la zone de projet doit être calculé.
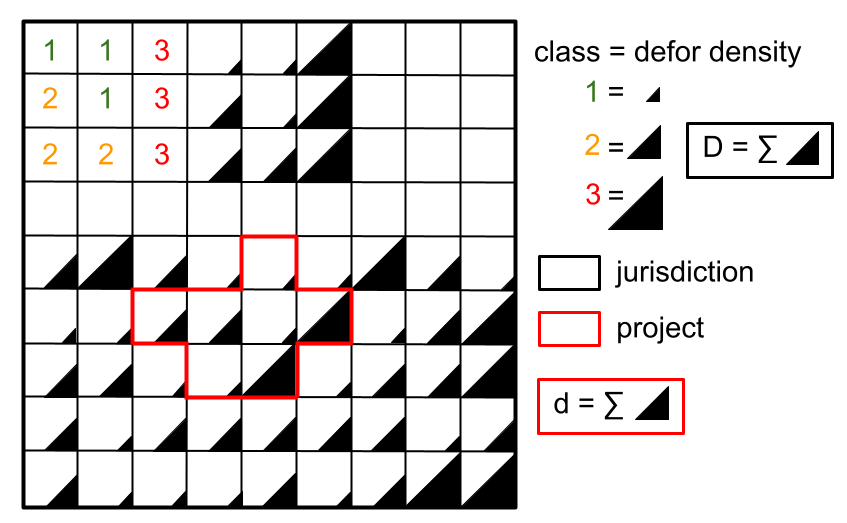
Attribution de la déforestation à des projets au sein de la juridiction.#
Le plugin QGIS deforisk inclut un utilitaire pour faciliter l’allocation de la déforestation aux projets. Avant de l’utiliser, vous pouvez télécharger le fichier vectoriel définissant les frontières d’un faux projet en Martinique (project_borders_MTQ_jurisdiction.gpkg).
Juris. risk map: Fichierprob_icar_t3.tifcorrespondant à la meilleure carte de risque.Table. with defor. rates: Fichierdefrate_cat_icar_forecast.csvpour la table avec les taux de déforestation du modèle icar à t3 pour chaque classe de risque de déforestation.Projet borders: Fichierprojet_borders_MTQ_jurisdiction.gpkg.Juris. deforestation (ha): 4000. Environ 400 ha ont été déforestés chaque année en 2010–2020 en Martinique.Length forecast period (yr): 10.Get deforestation density map (ha/pixel/yr): coché.
En appuyant sur le bouton Run dans cette boîte, on calcule le facteur d’ajustement et la densité de déforestation pour chaque classe de risque en utilisant la déforestation totale prévue au niveau de la juridiction (\(D=4000\)) et les taux de déforestation spatiaux relatifs du modèle. Ensuite, la carte de risque avec les classes de risque de déforestation est découpée aux limites du projet et le nombre de pixels de forêt dans chaque classe de risque est calculé au niveau du projet. Enfin, la déforestation prévue au niveau du projet est obtenue en additionnant les densités de déforestation de chaque pixel au sein du projet. Un fichier raster avec la densité de déforestation pour chaque pixel de forêt est également produit.
Un dossier outputs/allocating_deforestation est créé avec le fichier defor_project.csv indiquant la déforestation prévue (106,7 ha) pour la période 2020–2030 pour le projet :
period |
length (yr) |
deforestation (ha) |
|---|---|---|
annual |
1.0 |
10.7 |
entire |
10.0 |
106.9 |